死机问题分析指南¶
1. 思澈死机现场保存和分析指南¶
1.1 死机分类¶
本平台上的死机主要分为两类:
ASSERT
断言,由
RT_ASSERT触发,在log 里会显示触发的函数名和行数。发生断言时,error_reason的值为RT_ERROR_ASSERT。HWFAULT
CPU触发的硬件异常,常见有访问非法地址、非法指令等,在log 中会显示具体的异常类型,比如
bus fault、mem management fault、usage fault。发生硬件异常时,error_reason的值为RT_ERROR_HW_EXCEPTION。
1.2 死机分析方法¶
死机离线分析主要借助log和dump:
log:异常后会打印死机原因(断言或HW Fault)、系统信息(线程状态、heap、ipc信息等)。
dump:dump内存,可用Trace32恢复现场来分析。
除Trace32外,还有其它一些在线调试手段:比如Ozone、j-link(此处不做介绍)。
1.3 保存死机现场(抓dump)¶
1.3.1 通过BAT保存现场(Jlink)¶
操作步骤:
连接JLink仿真器到目标板(没有Jlink的芯片需要打开 SifliUsartServer.exe 用DBGUART模拟Jlink)
确认Jlink连接OK后,运行
save_ram_*.bat(如下图,根据对应芯片选择bat脚本)即可自动保存现场。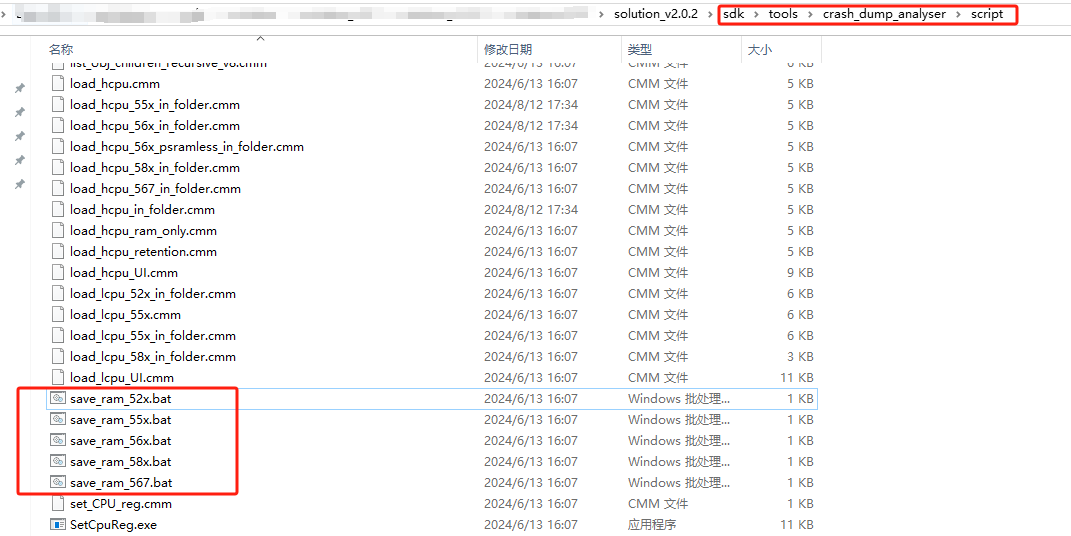
保存完成后,会在script目录下生以下bin文件(不同芯片保存生成的文件会有差异,下图以561为例):
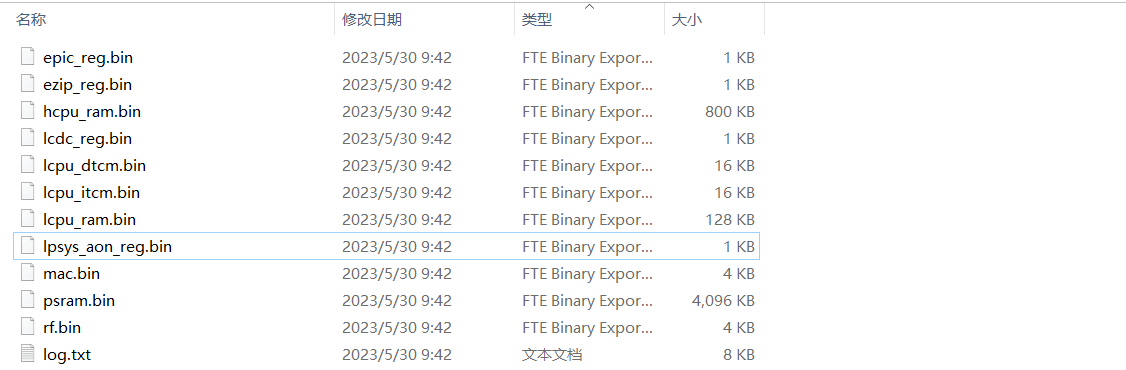
注意:保存完成后,建议检查一下各个bin的更新日期、大小,以确保保存成功;如不成功,可以先确认一下Jlink是否连接OK。
1.3.2 通过AssertDumpUart工具保存现场(UART)¶
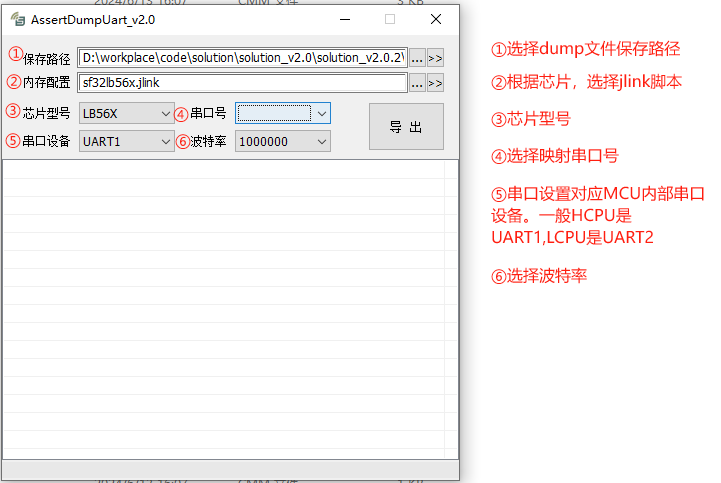
该工具直接连接debuguart口,然后执行对应的jlink脚本保存现场。
操作步骤:
双击打开
/sdk/tools/crash_dump_analyser/script/AssertDumpUart.exe。设置对应的jlink脚本、芯片型号、串口号、波特率、串口设备。
点击导出即可。
1.4 死机现场恢复(Trace32)¶
1.4.1 准备¶
dump bin :通过
BAT或者AssertDumpUart工具保存的死机bin文件。axf文件/elf文件(gcc编译环境):
1.4.2 恢复现场步骤:¶
将dump bin和axf/elf放在同一目录
运行t32marm.exe
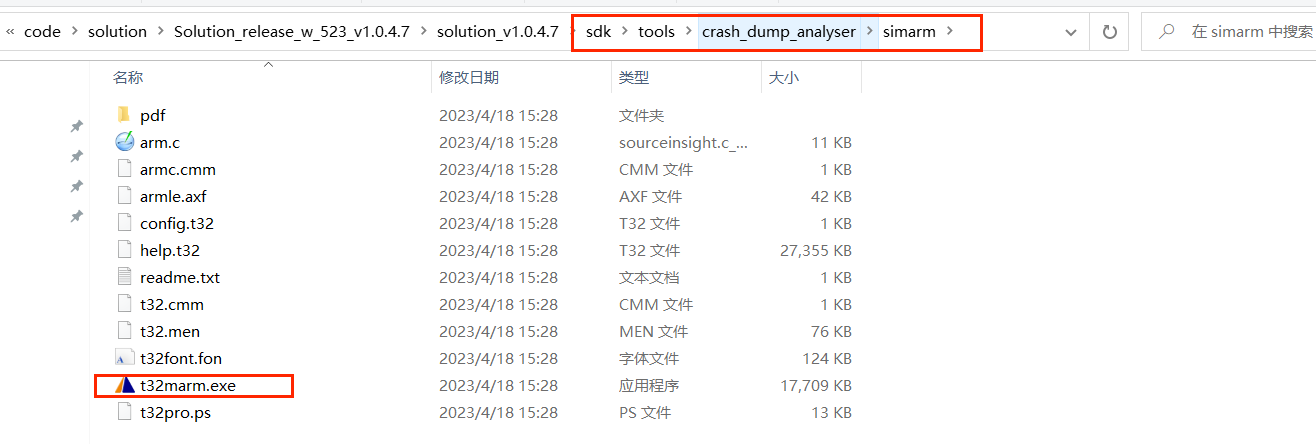
File - Run Script 运行恢复脚本:
根据芯片、配置、恢复HCPU、恢复LCPU选择对应的脚本即可(不同的基线版本,脚本可能会有更新)。
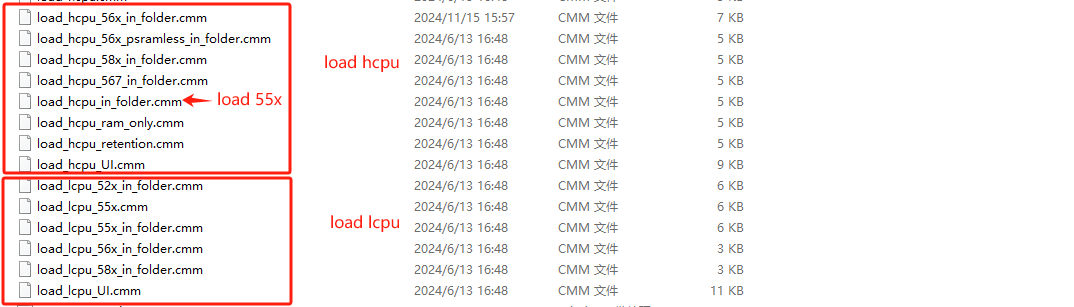
另外,提供了两个通用脚本,当没有芯片专用脚本时,可用于恢复现场:
load_hcpu_UI.cmm:用于恢复HCPUload_lcpu_UI.cmm:用于恢复LCPU
下图以HCPU通用脚本为例(LCPU通用脚本同操作):
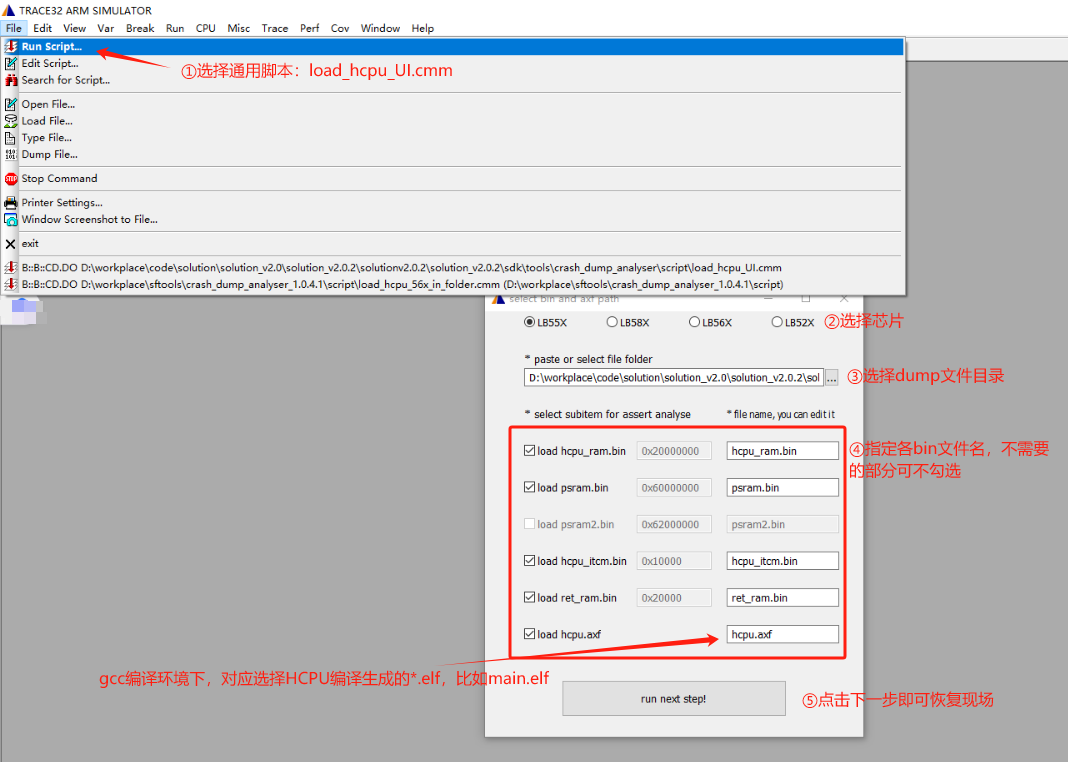
恢复成功:
恢复成功会自动打开以下窗口:task list(任务列表)、heap allocation(内存概况,包含sys heap、memheap)、timer list(定时器列表)、task switch history(任务切换历史)、出错时的函数调用栈、error_reason(表示死机类型)。
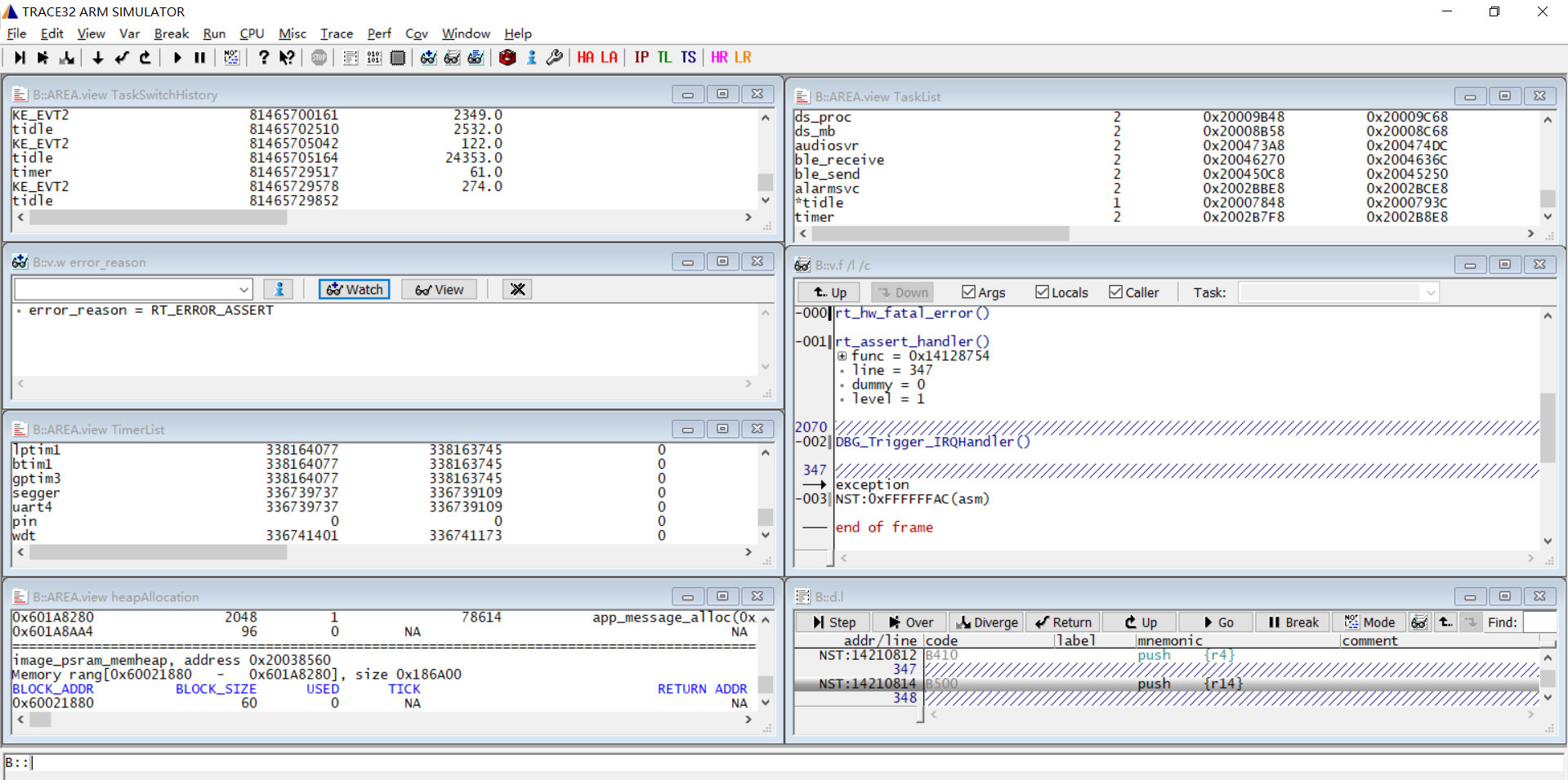
可以在Window菜单切换显示的窗口:
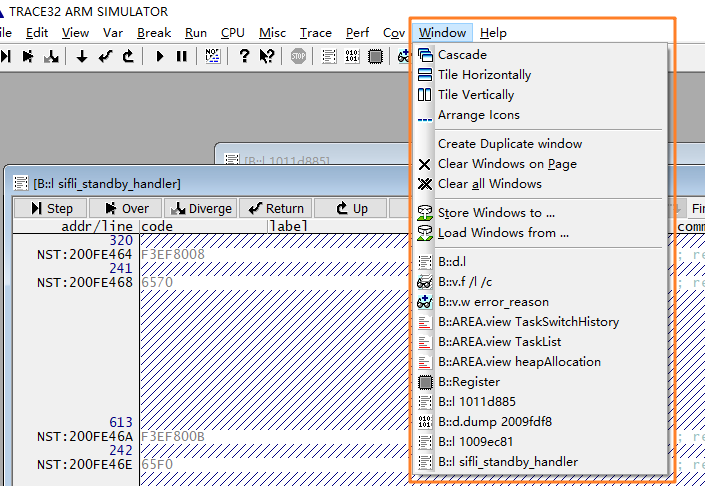
1.4.3 恢复失败情况处理¶
恢复失败时(没有显示异常调用栈),可先确认是不是存在以下情况:
dump文件保存异常(比如0字节)。
axf/elf文件和当前异常机器的软件版本不对应(一般需要一次编译生成的)。
如排除以上情况,可能是保存异常,可以尝试以下几种方法:
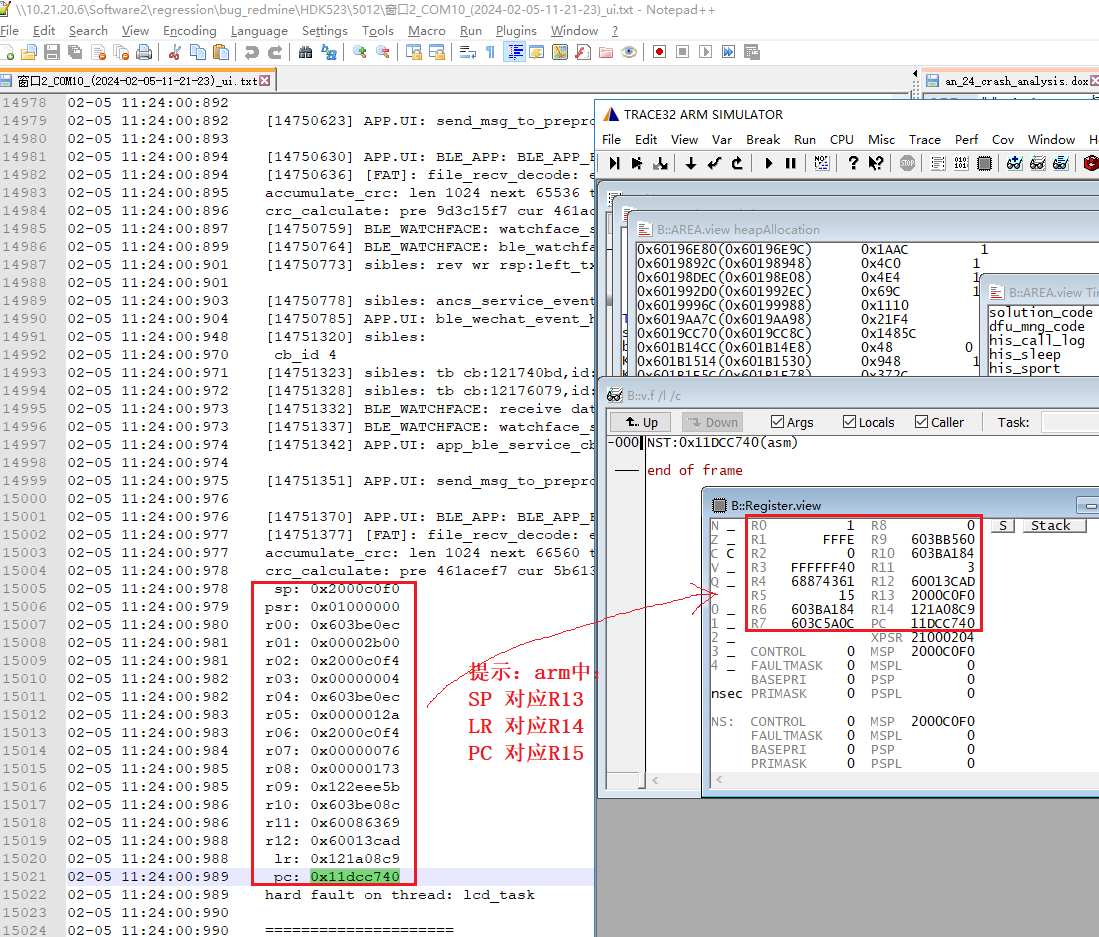
从串口log里面打印的16个寄存器中,回填到trace32的register窗口中:
从Jlink halt的log信息加载现场栈。
HR(HCPU Registers)按钮/LR(LCPU Registers)按钮用于恢复没有走到异常处理程序的CPU寄存器,点击按钮后选择导出现场的log.txt文件,他将把里面的寄存器回填到trace32: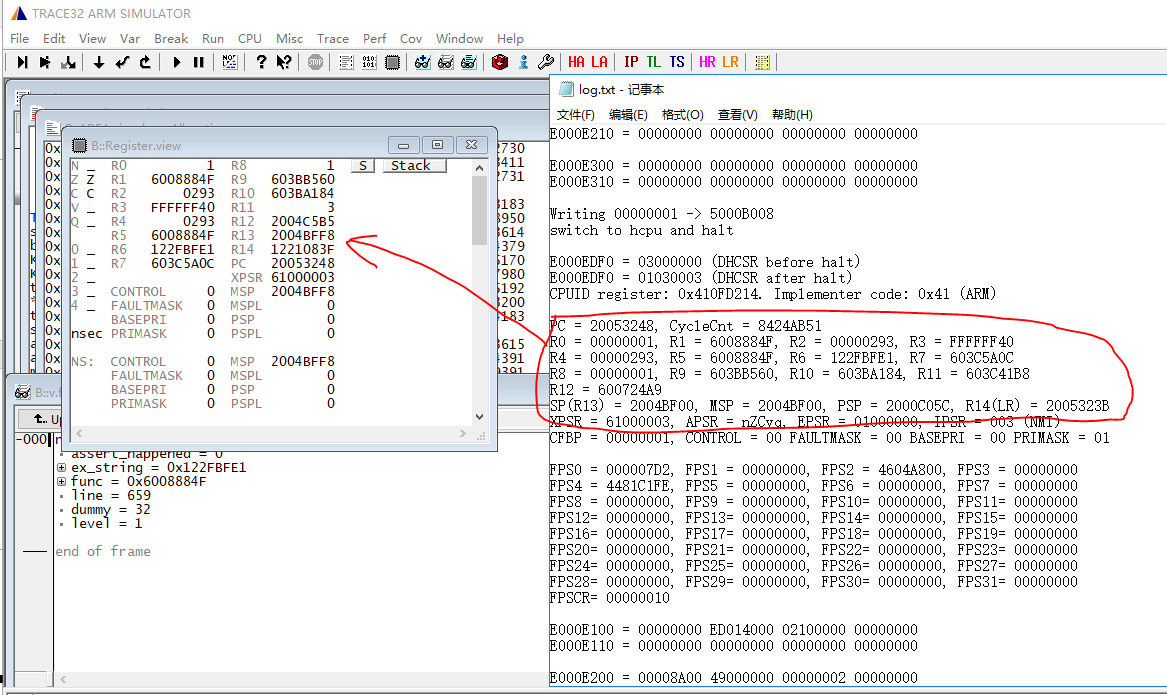
从
saved_stack_pointer/saved_stack_frame加载寄存器。
saved_stack_pointer/saved_stack_frame如果有保存值,可以将值对应回填到register窗口中: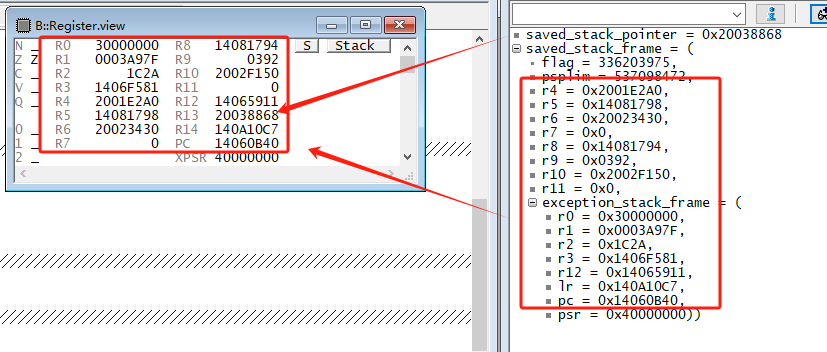
如果是PC为空,
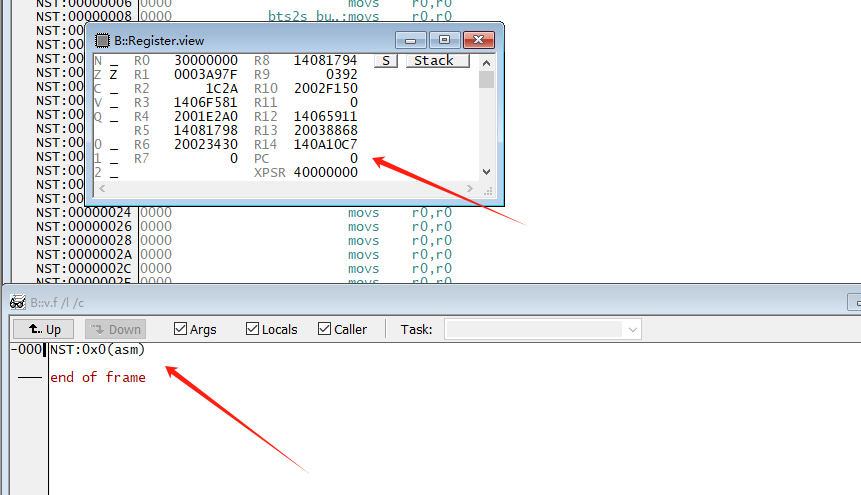
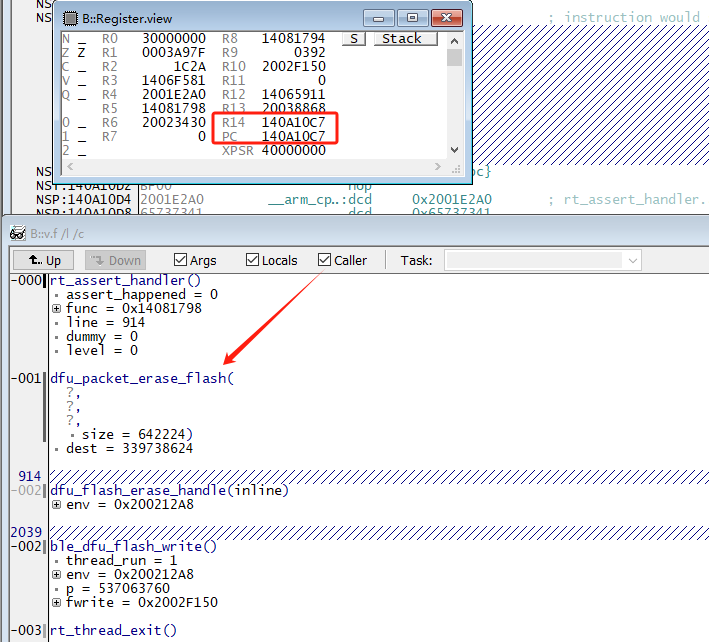
可以简单设置pc=lr(r14)来尝试查看函数调用关系:
1.5 常用命令(Trace32)¶
1.5.1 查看寄存器:¶
菜单:View – Registers
命令窗口:B::Register
1.5.2 查看变量:¶
菜单:View – Watch
命令窗口:B::Var.Watch
1.5.3 查看汇编:¶
菜单:View – List Source
命令窗口:B::List symbol/address
1.5.4 查看内存:¶
菜单:View – Dump
命令窗口:Data.dump address
1.6 扩展脚本(Trace32):¶
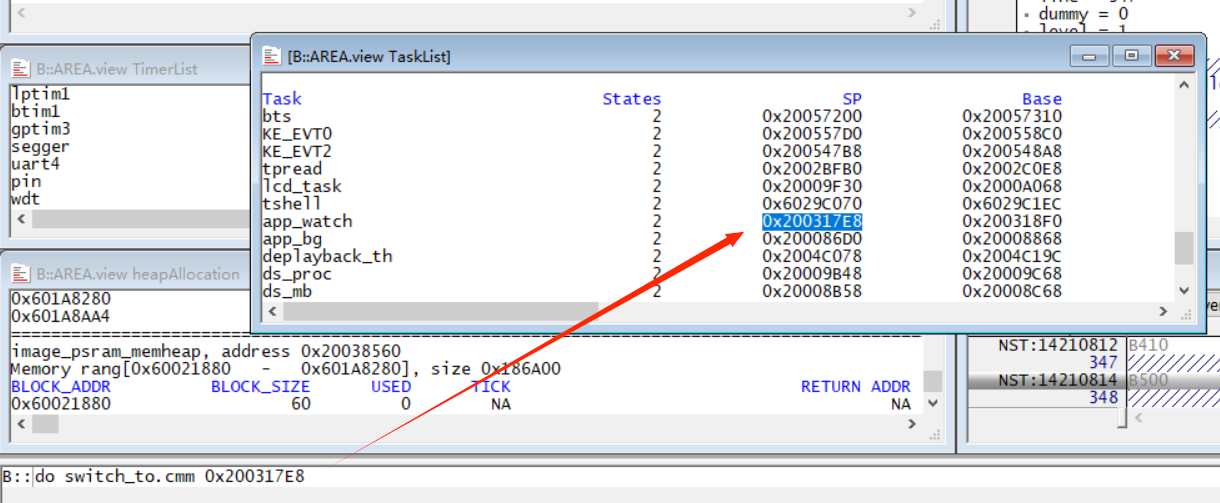
1.6.1 switch_to.cmm:¶
可用于切换task,命令格式:
do switch_to.cmm [task SP address]
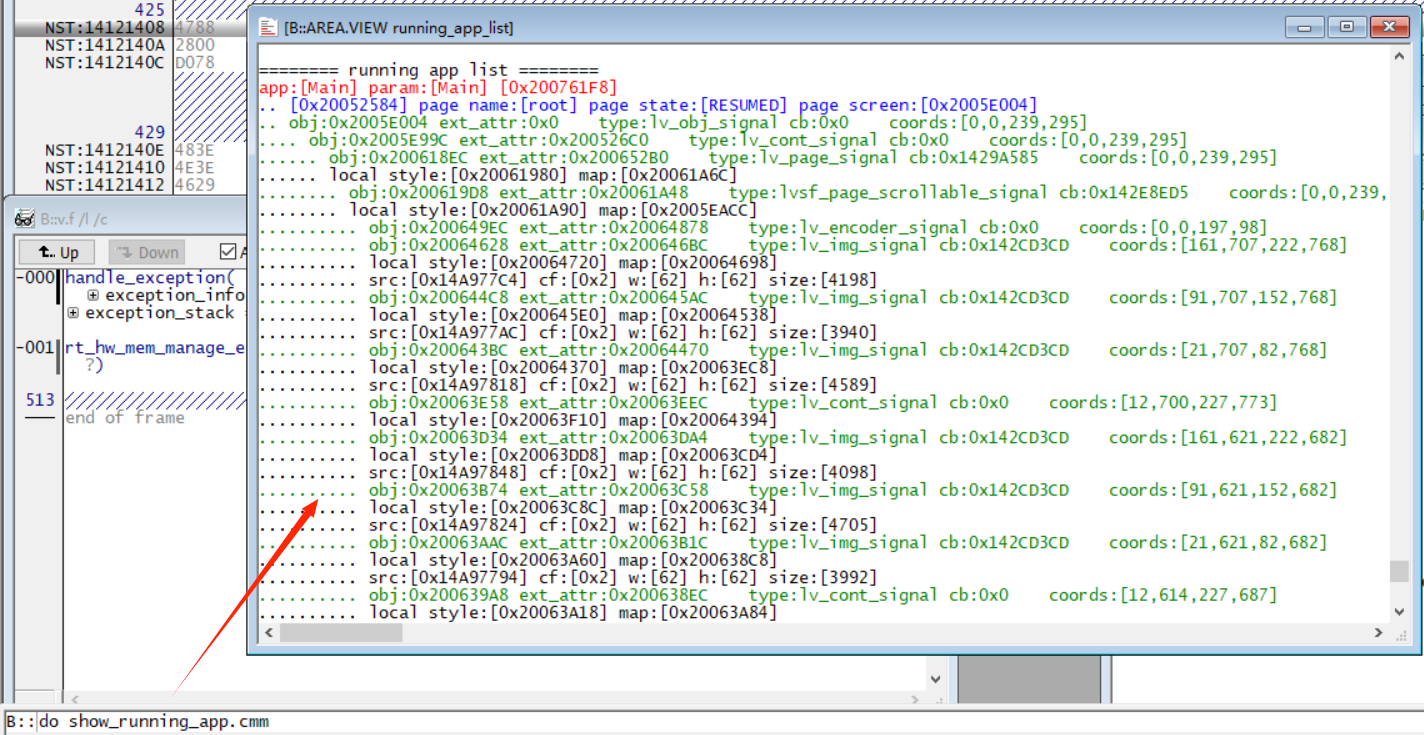
1.6.2 show_running_app.cmm:¶
可列出当前running app下的obj list,命令格式:
do show_running_app.cmm
1.7 常见死机案例¶
1.7.1 断言¶
SF55X/56X都是双核,当一个核发生异常后,会通知另外一个核触发断言。
HCPU log 打印如下断言(下图是SF56x的打印,SF55x机制略有不同,会直接打印HCPU crash/LCPU crash),表示是LCPU先发生异常,需要分析LCPU状态(反之亦然):

LCPU log显示有发生断言,断言函数和所在行数都有打印。

使用trace32恢复LCPU现场,通过dump也可以看到断言位置:

1.7.2 HW Fault¶
查看log,显示在app_watch发生HW Fault:
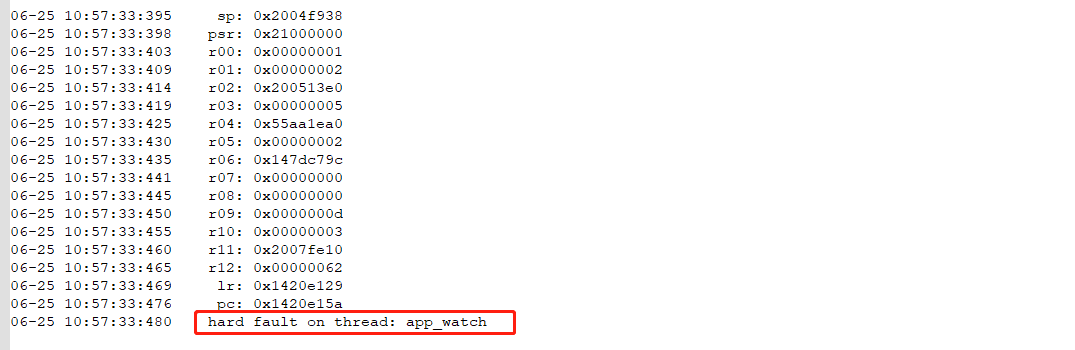
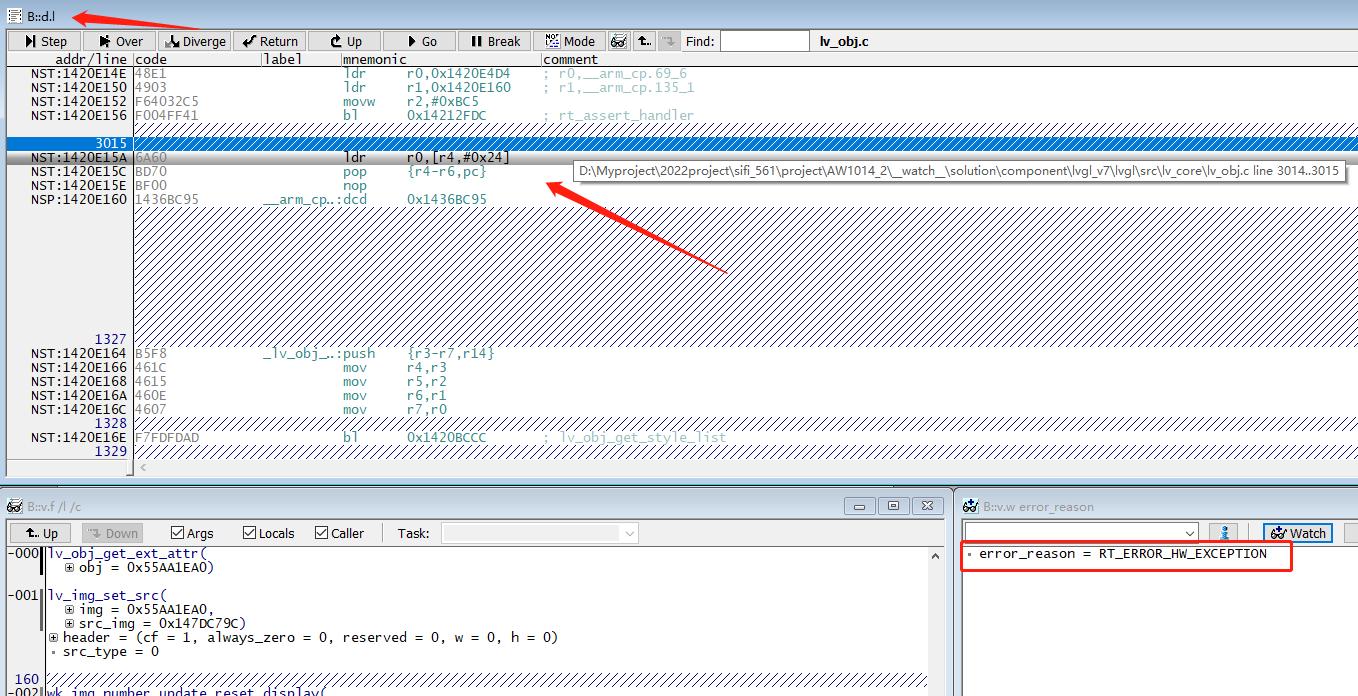
恢复dump,error_reason = RT_ERROR_HW_EXCEPTION表示是发生了HW Fault(bus fault , 错误地址0x55AA1EC4)。可以从list窗口看到当前发生异常的位置:lv_obj.c line 3015发生异常。

obj=0x55AA1EA0,明显obj指向无效地址。明确基本原因和位置后,即可结合代码进一步定位。
1.7.3 内存泄漏¶
Solution内存管理方案在《SiFli-Solution内存管理介绍》中有专门介绍,此处不再赘述。当内存不足时,malloc会触发断言。异常后,可通过log、dump来确认当前内存使用情况:


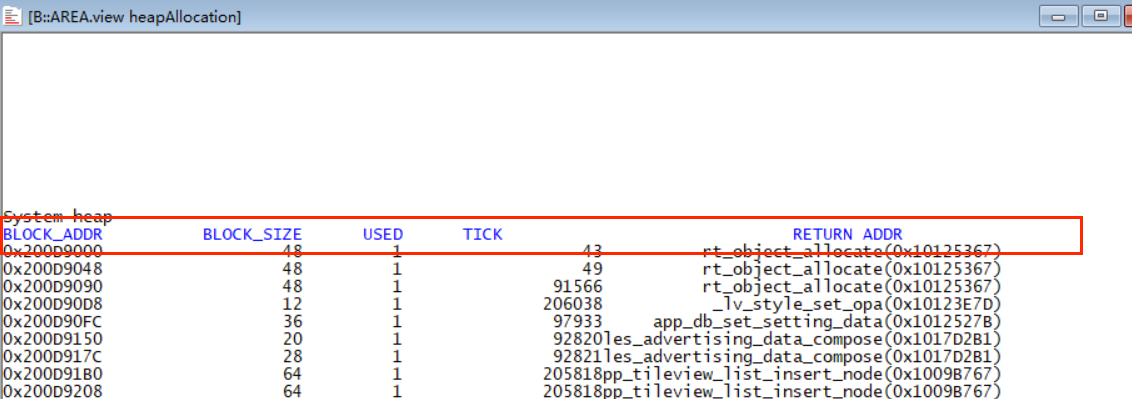
不同的malloc接口使用的heap有所差异(常用rt_malloc是从sys heap申请内存),如确定对应heap的内存不足,可通过heap allocation窗口来是否存在泄漏以及可能泄漏点:
USED为1表示申请未释放,为0表示已经释放:
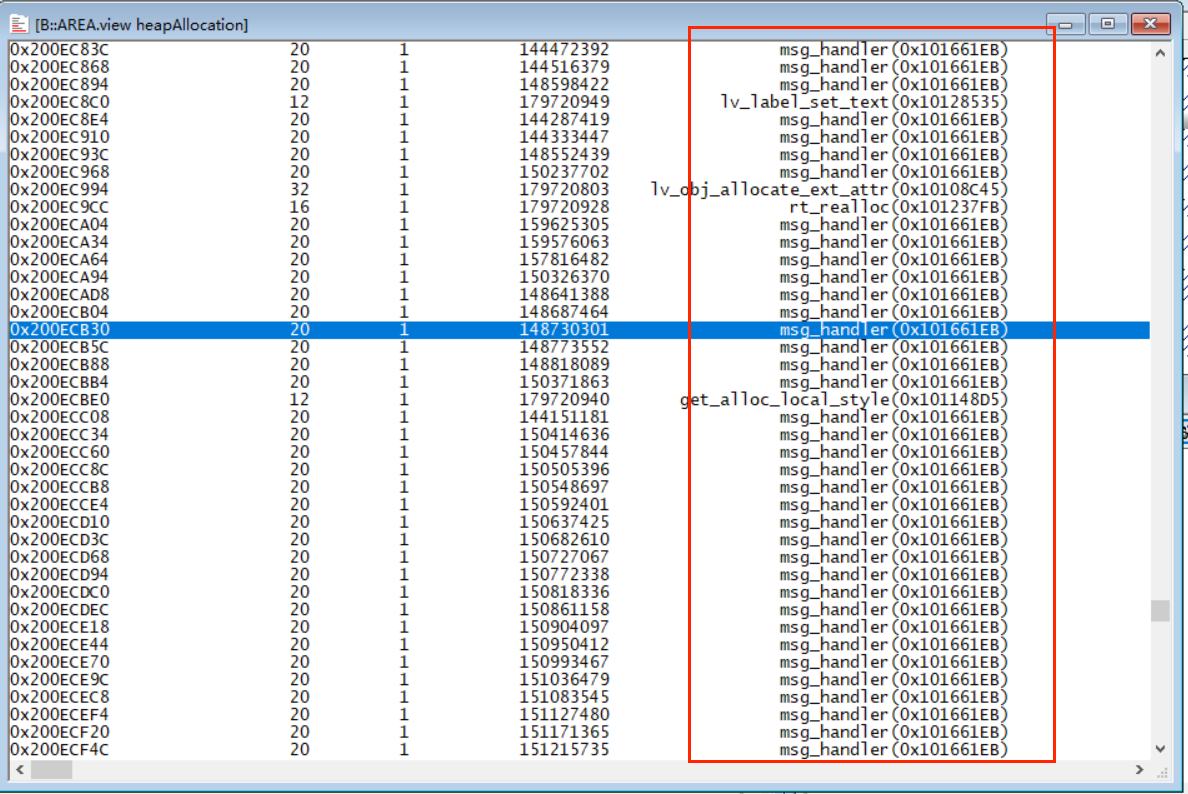
如下为例,可以看到有很多msg_handler申请的内存没有释放,基本可以确定泄漏,需要针对具体代码查看msg_handler申请的内存是不是有正常释放:
1.7.4 Data service 死机¶
data_send_proxy 断言, 对应的log和dump信息如下:
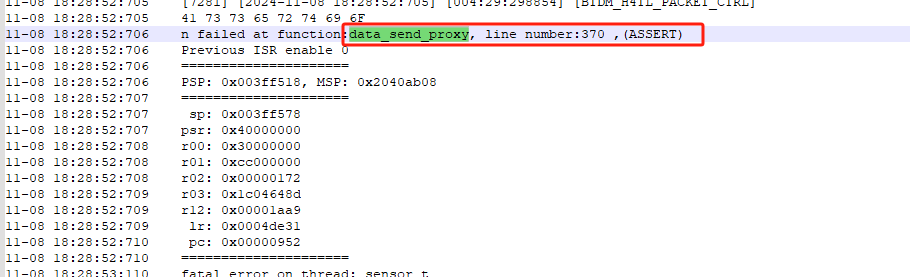
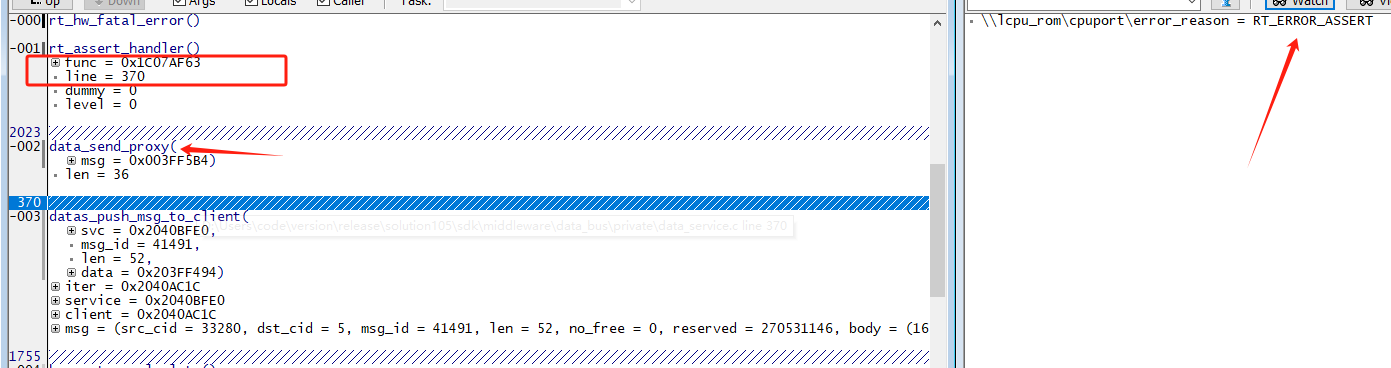
断言原因:data service发送队列满,超时(固定1s)断言。
如何确认data service存在发送队列满:
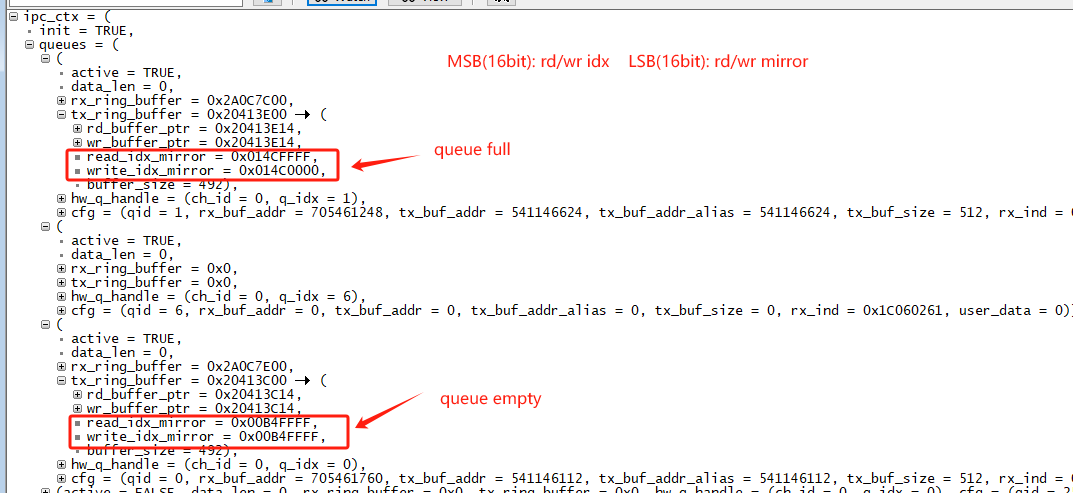
查看ipc_ctx.queues[4],这里最大支持同时active 4路,查看active状态的queue.tx_ring_buffer状态:
rd_idx_mirror和 write_idx_mirror的高16位相同、低16位不同时,表示队列满;rd_idx_mirror和 write_idx_mirror的高16位相同、低16位也相同时,表示队列空;
如下图,则存在queue队列满:
此类问题可能的原因:
发送频率过快,接收速度跟不上。比如,<1ms内的间隔快速发送,有可能导致发送超时。可能需要结合大小核串口log协助分析。
接收方发生异常,比如死机、硬件异常(例如静电打挂)等情况。
高优先级线程影响消息接收。